

Cet article a été sponsorisé par JetOctopus. Les opinions exprimées dans cet article sont celles du sponsor.
Comment puis-je optimiser mon site pour ChatGPT et Perplexity, pas seulement pour Google ?
Comment puis-je savoir si des robots IA explorent réellement mon site ?
Comment ma stratégie de référencement technique devrait-elle changer pour AI Search ?
Une part importante des impressions de recherche de votre site en 2026 sont générées par des machines effectuant des recherches pour le compte des humains.
Ces machines ne se soucient pas du classement de vos mots clés. Ils se soucient de savoir si votre :
- HTML se charge proprement en moins de 200 millisecondes
- La page détaillée du produit est accessible en moins de quatre clics
- Le contenu répond à une question spécifique de neuf mots qui n’est jamais apparue dans aucun outil de recherche de mots clés au cours de votre carrière.
Ce n’est pas de la spéculation. C’est ce que nous montrent régulièrement les données des journaux de nos serveurs sur des centaines de sites Web d’entreprise depuis la mi-2025.
Que se passe-t-il réellement sur votre site
Mon collègue Stan a signalé une tendance dans un message Slack : la longueur des requêtes augmentait à des rythmes qui ne correspondaient pas au comportement humain.
Un taux de croissance de 161 % des requêtes de 10 mots d’une année sur l’autre n’est pas dû au fait que les utilisateurs sont soudainement devenus plus verbeux. Il est piloté par des agents d’IA qui décomposent une invite utilisateur unique en dizaines de sous-requêtes parallèles, un processus que les chercheurs appellent désormais « fan-out ».
Croissance de la longueur des requêtes en 2025
Le dégradé est le révélateur. Le comportement de recherche humain ne mesure pas cela clairement en fonction du nombre de mots. Les machines le font. En octobre 2025, les requêtes de plus de 7 mots atteignaient près de 1 % du volume total des requêtes, soit environ le triple de leur part historique.
Le CTR est plus révélateur que le volume. Alors que le nombre d’impressions pour les requêtes de 10 mots a grimpé de 161 %, le taux de clics s’est effondré à 2,26 %, contre 8 à 11 % en 2023.
L’IA lit votre page, extrait la réponse, la synthétise pour l’utilisateur. Votre site ne reçoit jamais la visite.
Nous appelons cela des « impressions fantômes ». Ce sont de véritables signaux indiquant que votre contenu est évalué dans les chaînes de raisonnement de l’IA. Si vous les excluez de vos rapports parce qu’ils ne génèrent pas de trafic, vous volez à l’aveugle.
Les trois robots visitant votre site et leur impact sur la visibilité SERP
Tous les robots d’exploration d’IA ne sont pas égaux, et les traiter comme une seule catégorie est la première erreur que commettent la plupart des référenceurs techniques.
Exploration des robots d’entraînement au sens large et ignorez la profondeur des clics. Une visite de formation signifie que l’IA sait que votre contenu existe, et non que les utilisateurs le verront un jour.
Bots de recherche IA déposez rapidement au-delà de deux ou trois clics depuis la page d’accueil et visitez généralement chaque page une seule fois par mois.
Bots utilisateurs IA sont initiés lorsqu’une personne réelle pose une question dans ChatGPT, Perplexity ou Claude, et que l’IA recherche la réponse en son nom. Ce sont les seules visites qui se traduisent par une réelle visibilité de l’IA.
| Type de robot | Qu’est-ce qui le déclenche | Profondeur d’exploration | Impact sur la visibilité de l’IA |
| Bots de formation | Cycles éducatifs modèles | Profond – ignore la distance de clic | Aucun directement. Sensibilisation seulement. |
| Bots de recherche IA | Nouvelle découverte d’URL et nouveau contenu | Peu profond — ~ 1 visite/mois au-delà de 2 à 3 clics | Gardien critique. S’il manque une page, les robots utilisateurs ne la trouveront pas non plus. |
| Bots utilisateurs IA | Requête d’utilisateur réel dans ChatGPT / Claude / Perplexité | Sélectif – motivé par la vitesse et la structure | Haut. Proxy le plus proche d’une impression IA. |
Votre site peut faire l’objet d’une exploration intensive de la part des robots de formation et de recherche tout en étant complètement absent des réponses générées par l’IA. Si vous ne segmentez pas le trafic des robots IA par type dans votre analyse de journaux, vous n’avez aucune idée du tiers de l’iceberg que vous mesurez.
Quels signaux SEO les LLM respectent-ils ?
Robots.txt est votre principal levier.
La plupart des grandes plateformes d’IA (ChatGPT, Claude, Gemini) suivent les directives robots.txt. Perplexity est une exception partielle : PerplexityBot respecte robots.txt, mais pas Perplexity-User, le bot déclenché par l’utilisateur. Cloudflare l’a confirmé dans une enquête. La plupart des sites n’ont pas audité leur fichier robots.txt en pensant à l’accès à l’IA. Fais-le.
Les plans de site sont largement pris en charge.
ChatGPT, Claude et PerplexityBot utilisent tous des plans de site XML pour la découverte d’URL. Gardez-les précis.
Signaux les mieux conservés pour les efforts de référencement et de classement
Ces signaux ci-dessous ne semblent pas avoir d’impact sur la visibilité de l’IA, mais restent essentiels pour le classement des requêtes qui déclenchent toujours les SERP traditionnels.
Les balises canoniques et les directives noindex ne font rien pour les robots IA.
Les robots d’exploration IA ne créent pas d’index de recherche, ils n’ont donc aucune utilité pour ces méta-signaux. Le contenu masqué à Google à l’aide de noindex est entièrement visible pour le robot d’exploration de ChatGPT.
LLM.txt ne fait rien.
Nos données de journal montrent que les principaux robots IA ne lisent pas ce fichier. N’investissez pas de temps ici.
Le rendu JavaScript est un angle mort critique.
La plupart des robots d’exploration d’IA (ChatGPT, Claude, Perplexity) ne rendent pas JavaScript. Si vos pages de produits chargent du contenu clé côté client, ces agents lisent un shell vide. Le rendu côté serveur est la seule architecture qui fonctionne universellement. L’exception est Google Gemini, qui utilise le même service de rendu Web que Googlebot.
Comment s’assurer que ChatGPT, Perplexity et LLM peuvent atteindre votre contenu
Les robots de recherche IA visitent les pages approfondies environ une fois par mois et diminuent fortement au-delà de trois clics depuis la page d’accueil. Les pages contenant les informations les plus spécifiques et les plus fiables sont souvent les plus difficiles à atteindre pour les agents.
Le correctif: Élevez vos pages profondes les plus précieuses grâce à des liens internes, en vous assurant qu’elles sont accessibles en quatre clics.
Les pages explorées par les robots d’entraînement mais jamais atteintes par les robots utilisateurs sont vos cibles les plus prioritaires. Les pages que les robots utilisateurs d’IA visitent fréquemment vous indiquent ce qu’il faut mettre à l’échelle : plus de contenu couvrant le même groupe de sujets et la même profondeur.
Optimisez le contenu pour des requêtes plus longues et distribuées
95 % des requêtes générant des citations d’IA n’ont aucun volume de recherche mensuel. Ce sont des sous-requêtes synthétiques générées par des modèles d’IA. Mais ils apparaissent dans GSC : impressions, aucun clic, longueurs de requêtes que vous ne cibleriez jamais volontairement.
Comment trouver des opportunités de requête de répartition
Pour afficher les requêtes qui valent la peine d’être poursuivies, connectez votre API GSC à JetOctopus (pour contourner la limite de 1 000 lignes de l’interface utilisateur) et filtrez par : longueur de requête supérieure à 7 mots, impressions inférieures à 50, clics à 0, au cours des 3 derniers mois. Il s’agit de votre matrice d’opportunités de diffusion, les questions exactes que les agents d’IA posent à propos de votre contenu.
Types d’invites les plus répandus
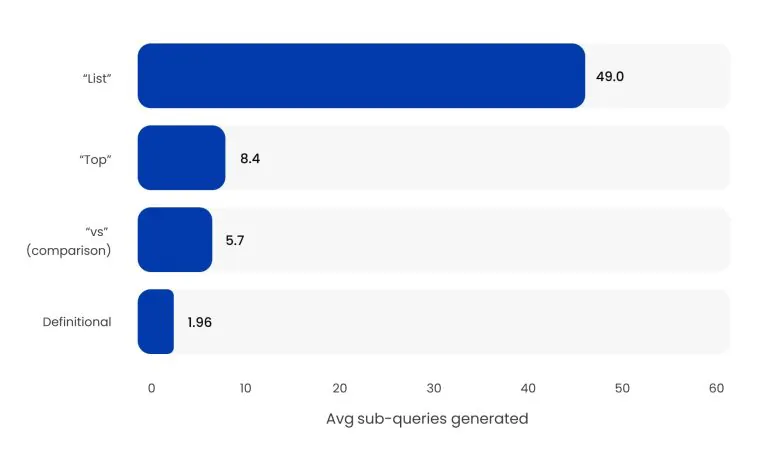
Si votre contenu n’est pas structuré pour répondre aux requêtes de liste et de comparaison, avec des classements explicites, des avantages/inconvénients et des spécifications côte à côte, vous laissez la surface de diffusion la plus élevée non optimisée.
Les requêtes d’intention « évaluation de produits » sont passées de 239 en juin 2025 à plus de 40 000 en septembre 2025. Cette augmentation de 16 000 % est due au fait que les agents d’IA récoltent systématiquement des données d’opinion structurées. Si vos pages de produits manquent de cette profondeur, vous êtes invisible pour cette récolte.
L’audit technique : où Commencer
Étape 1 : Identifier le trafic des robots des utilisateurs IA dans les journaux
Extrayez les journaux bruts du serveur (Apache/Nginx) et exportez toutes les lignes contenant ces agents utilisateurs : OAI-SearchBot et ChatGPT-User, PerplexityBot et Perplexity-User, Claude-SearchBot et Claude-User. Regroupez ensuite manuellement les accès par modèles d’agent utilisateur et points de terminaison dans une feuille de calcul. Pour distinguer les robots de formation des robots utilisateurs, vous devrez conserver votre propre liste de classification, qui change souvent et n’est pas standardisée.
Dans JetOctopus Log Analyzer, cette segmentation est intégrée : filtrez par type de bot (formation, recherche et utilisateur) en quelques clics et voyez immédiatement quelles pages les robots utilisateurs de l’IA visitent (votre contenu visible par l’IA, prêt à évoluer) par rapport aux pages que les robots de formation frappent mais que les robots utilisateurs n’atteignent jamais (vos cibles de correction les plus prioritaires).
Étape 2 : Audit de l’accessibilité technique des pages profondes
Choisissez un échantillon d’URL profondes et vérifiez la taille de la charge utile HTML, confirmez que le contenu clé n’est pas injecté via JavaScript en affichant le HTML brut, simulez la profondeur d’exploration en comptant les clics depuis la page d’accueil et testez le temps de chargement dans Chrome DevTools ou Lighthouse. Vérifiez également si le contenu important se trouve derrière des accordéons ou des éléments « Afficher plus » : ceux-ci nécessitent une exécution JavaScript que les robots IA ignorent complètement. Pour les grands sites comportant des milliers de pages profondes, cette approche d’échantillonnage manque beaucoup. Les agents IA ne cliquent pas. Si les informations n’apparaissent qu’après interaction de l’utilisateur, elles n’existent pas pour ces robots d’exploration.
Étape 3 : Nettoyez votre fichier Robots.txt
Ouvrez votre robots.txt et examinez toutes les directives Disallow et Allow pour chaque agent utilisateur ligne par ligne. Les robots IA suivent les règles d’interdiction, alors assurez-vous de ne pas bloquer accidentellement des URL importantes. Testez manuellement les URL clés pour confirmer qu’elles ne sont pas bloquées. Un audit de 30 minutes ici peut vous empêcher de bloquer les robots d’exploration auxquels vous souhaitez accéder ou d’exposer du contenu que vous préférez exclure.
Étape 4 : Cartographiez vos impressions fantômes
Exportez les données des rapports GSC Performance filtrées par impressions avec zéro clic. En raison de la limite de 1 000 lignes de l’interface utilisateur, vous devrez utiliser l’API GSC ou exporter en morceaux par date et requête, puis fusionner les ensembles de données dans des feuilles de calcul ou BigQuery. Tenez également compte de la fréquence des requêtes : les requêtes longues apparaissant quotidiennement ne sont probablement pas des diffusions.
Connectez votre API GSC à JetOctopus pour contourner la limite de lignes et créer automatiquement votre matrice d’opportunités de diffusion : les questions exactes que les agents d’IA posent sur votre contenu, prêts à agir.
Étape 5 : Surveiller les modifications
Configurez un processus d’exportation récurrent : extrayez les données GSC mensuellement et comparez les impressions au fil du temps, réexécutez les scripts d’analyse des journaux et l’activité des robots, suivez les Core Web Vitals séparément dans PageSpeed Insights ou CrUX. Vous finirez par assembler plusieurs sources de données sans alerte unifiée, ce qui rendra difficile la détection précoce des régressions.
Les alertes JetOctopus couvrent exactement cela : des notifications unifiées pour les changements dans l’activité des robots IA ainsi que le comportement de Googlebot, les Core Web Vitals, les problèmes de référencement sur la page et les baisses d’efficacité SERP, afin que vous puissiez détecter les régressions avant qu’elles ne s’aggravent.
Le nouveau KPI : Accessibilité technique
Le référencement en 2026 se restructure autour d’une contrainte : un agent d’IA peut-il explorer, atteindre et extraire un fait de votre 50 000ème page produit en moins de 200 millisecondes ?
Si la réponse est non, votre classement, vos backlinks et la qualité de votre contenu ne sont plus pertinents pour une part croissante des interactions de recherche. Les machines cherchent. La question est de savoir à quelle vitesse vous pouvez voir ce qui se passe réellement.
Commencez par vos journaux. Tout le reste découle de là.
| Vous voulez voir exactement comment les robots IA interagissent avec votre site : Quelles pages atteignent-ils, lesquelles ignorent-ils et où se cachent vos opportunités de diffusion ? Réservez une présentation en direct de la plateforme JetOctopus. Nous extrairons vos données de journal réelles et vous montrerons ce que vos rapports GSC ne vous disent pas. |