

Depuis que nous sommes capables de produire du contenu à grande échelle grâce à l’IA, des captures d’écran graphiques ont été publiées sur X et LinkedIn, généralement des études de cas ou dans le cadre de supports de vente.
Un référenceur que je connais bien, Martin Sean Fennon, a partagé un exemple d’étude de cas de marque en cours, mettant à l’échelle le contenu via l’IA et comment le contenu est reçu (grâce à une mesure du trafic tierce).
Le problème n’est pas toujours que le contenu a été produit par l’IA ; cela a toujours été un bon différenciateur sur lequel rejeter la faute, car il y a beaucoup plus de facteurs qui entrent en ligne de compte si le contenu est indexé ou non, et encore moins servi.
Le véritable problème réside dans le fait que la mise à l’échelle de la production de contenu, quelle que soit la méthode utilisée, introduit souvent une série de problèmes de contrôle qualité. L’IA est tout simplement le bouc émissaire le plus récent et le plus simple pour une rupture fondamentale du pipeline de contenu, qui comprend tout, de la stratégie de mots clés et de la sélection de sujets à l’édition, aux liens internes et à la distribution.
Cette allocation ne constitue toutefois pas une garantie de performance durable.
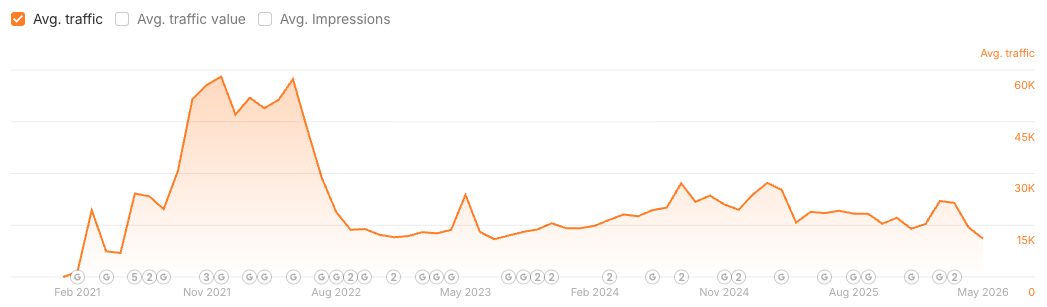
L’essor initial est souvent le résultat du traitement efficace par les systèmes de Google du contenu nouveau ou inédit, ce qui signifie qu’il bénéficie d’un « boost de fraîcheur ». Un boost de fraîcheur similaire est appliqué lorsque vous soumettez une URL via Google Search Console pour indexation.
Le seuil auquel nous sommes actuellement confrontés est de maintenir cette qualité et cette pertinence à grande échelle, une fois que la nouveauté initiale s’est dissipée et que l’effet « Montagne d’IA » s’est estompé, laissant derrière lui les défis sous-jacents liés à la qualité du contenu.
Lorsque vous introduisez de nombreuses nouvelles URL sur votre site Web, vous demandez à Google d’augmenter les ressources de votre site Web, et la manière dont Google alloue ces ressources est bien documentée.
Comme leur inventaire perçu ne correspond plus à votre inventaire réel, Google doit choisir dans quelle proportion du nouveau lot d’URL investir, ou s’il souhaite ou non investir dans un échantillon représentatif des nouvelles URL (potentiellement basé sur un modèle d’URL, par exemple un sous-dossier), puis voir comment les utilisateurs réagissent et interagissent avec le contenu.
Ce processus détermine si, moins l’augmentation de fraîcheur initiale, l’URL (et le contenu) est justifié de rester dans l’index et d’être servi.
Ce concept est directement lié au budget d’exploration et au seuil de qualité de Google. Si les exemples d’URL fonctionnent mal ou ne parviennent pas à atteindre une certaine barre de qualité une fois que la nouveauté initiale s’est dissipée, le reste du contenu mis à l’échelle a souvent du mal à gagner du terrain.
Il convient également de noter que le seuil n’est pas statique et change au fil du temps à mesure que du contenu de meilleure qualité est publié, comme l’a noté Adam Gent, et variera selon le sujet, car toutes les requêtes ne méritent pas d’être fraîches.
Le contenu généré par l’IA entraînant une augmentation initiale du trafic, rapidement suivie d’un plateau ou d’un déclin, constitue une bonne publication sociale, mais il met également en évidence une compréhension clé selon laquelle le problème ne vient pas de l’IA elle-même, mais d’un échec fondamental dans la stratégie de contenu et le contrôle qualité à grande échelle.
L’IA ne fait qu’amplifier les faiblesses existantes. Le « boost de fraîcheur » que reçoivent les nouvelles URL masque ces problèmes sous-jacents, créant une illusion temporaire de succès.
Le véritable obstacle est le seuil de qualité de Google, car Google doit gérer les ressources et devenir plus strict sur ce qu’il explore (et à quelle fréquence) et sur ce qui est conservé dans l’index prêt à être servi.
En évaluant un échantillon de nouvelles URL pour voir si elles engagent réellement les utilisateurs et maintiennent leur pertinence, cela évite de gaspiller des ressources. Si cet échantillon, ou le contenu à plus grande échelle, n’atteint pas le seuil de qualité actuel, alors les ressources seront retirées et nous assisterons à davantage de scénarios « Mt. AI ».
Passer de l’échelle de production au maintien de la qualité à grande échelle
C’est important car s’appuyer uniquement sur l’IA pour le volume est une mesure vaniteuse qui garantit un gaspillage de ressources à long terme.
L’accent doit passer de l’échelle de production au maintien de la qualité à grande échelle.
Les marques doivent investir dans des processus éditoriaux robustes, une stratégie dirigée par l’humain et une assurance qualité méticuleuse (y compris les liens internes et la distribution) pour garantir que chaque élément de contenu, qu’il soit assisté ou non par l’IA, dépasse systématiquement le seuil évolutif de Google. Cela a été récemment décrit par Google à Toronto comme un contenu non marchand.
Ne pas le faire signifie rechercher constamment des augmentations de trafic éphémères au lieu de créer des performances organiques durables et faisant autorité.
Plus de ressources :