
![Structured Data In 2024: Key Patterns Reveal The Future Of AI Discovery [Data Study]](https://www.smartranking.fr/wp-content/uploads/2024/12/1733230861_Les-modeles-cles-revelent-lavenir-de-la-decouverte-de-lIA.png)
Le paysage des données structurées a subi une transformation significative en 2024, sous l’effet de l’essor de la recherche basée sur l’IA, de l’importance croissante du contenu lisible par machine et de la nécessité d’ancrer de grands modèles linguistiques sur des données factuelles.
Selon le dernier Almanach Web de HTTP Archivel'analyse des données structurées sur 16,9 millions de sites Web révèle un net changement de la mise en œuvre du référencement traditionnel vers le développement de graphes de connaissances plus sophistiqués qui alimentent les systèmes de découverte d'IA.
Alors que Google a déprécié certains résultats riches comme les FAQ et les HowTos en 2023, il a simultanément introduit un nombre sans précédent de nouveaux types de données structurées, notamment des listes de véhicules, des informations sur les cours, des locations de vacances, des pages de profil et des modèles de produits 3D.
En février 2024, la prise en charge des variantes de produits et de GS1 Digital Link a été étendue, suivie du lancement bêta des carrousels de données structurées en mars.
Cette évolution rapide témoigne d'un écosystème en pleine maturité dans lequel les données structurées servent non seulement à la visibilité des recherches, mais constituent également la base des réponses factuelles de l'IA, des modèles de langage de formation et des expériences de produits numériques améliorées.
Analyse et méthodologie
Les informations présentées dans cet article sont basées sur l'édition 2024 du chapitre Données structurées du Web Almanac de HTTP Archive. Le rapport annuel analyse l'état du Web en évaluant la mise en œuvre de données structurées sur 16,9 millions de sites Web. Ces ensembles de données sont publiquement interrogeable sur BigQuery dans les tables du `httparchive.all.*` tableaux pour la date date="2024-06-01" et s'appuie sur des outils tels que WebPageTest, Lighthouse et Wappalyzer pour capturer des mesures sur les formats de données structurés, les tendances d'adoption et les performances.
Tendances d'adoption des données structurées
L'analyse révèle une croissance intéressante dans les principaux formats de données structurées :
- JSON-LD atteint 41 % d'adoption (+7 % sur un an).
- RDFa maintient son leadership avec une présence de 66% (+3% sur un an).
- La mise en œuvre d'Open Graph atteint 64 % (+5 % sur un an).
- L'utilisation des balises méta X (Twitter) augmente à 45 % (+8 % par rapport à l'année précédente).
Cette adoption généralisée indique que les organisations investissent dans des données structurées non seulement pour la visibilité des recherches, mais également pour permettre à l'IA et aux robots d'exploration de comprendre et d'améliorer leurs expériences numériques.
Découverte de l'IA et graphiques de connaissances
La relation entre les données structurées et les systèmes d’IA évolue de manière complexe.
Alors que de nombreux moteurs de recherche d’IA générative développent encore leur approche pour exploiter les données structurées, des plateformes établies comme Bing Copilot, Google Gemini et des outils spécialisés comme SearchGPT semblent déjà démontrer la valeur de la compréhension basée sur les entités, en particulier pour les requêtes locales et la validation factuelle.
Formation et compréhension de l'entité
Les moteurs de recherche d’IA générative sont formés sur de vastes ensembles de données qui incluent un balisage de données structuré, influençant la manière dont ils :
- Reconnaître et catégoriser les entités (produits, emplacements, organisations).
- Réponses au sol. Nous le voyons dans des systèmes comme DataGemma qui utilisent des données structurées pour fonder les réponses sur des faits vérifiables.
- Comprendre les relations entre différents points de données. Cela est particulièrement évident lorsque schema.org est utilisé pour agréger des ensembles de données provenant de sources faisant autorité dans le monde entier.
- Types de requêtes spécifiques aux processus, comme les recherches d'entreprises locales et de produits.
Cette formation façonne la manière dont les systèmes d'IA interprètent et répondent aux requêtes, particulièrement visible dans :
- Requêtes commerciales locales où les attributs d'entité correspondent à des modèles de données structurées.
- Requêtes de produits qui reflètent les données structurées fournies par le commerçant.
- Informations du panneau de connaissances qui correspondent aux définitions d'entité.
Intégration des moteurs de recherche
Différentes plates-formes démontrent l'influence des données structurées à travers :
- Recherche traditionnelle : Des résultats riches et des panneaux de connaissances directement alimentés par des données structurées.
- Intégration de la recherche IA :
- Bing Copilot affichant des résultats améliorés pour les entités structurées.
- Google Gemini reflétant les informations du graphique de connaissances.
- Des moteurs spécialisés comme Perplexity.ai démontrant la compréhension des entités dans les requêtes de localisation.
- Dernière expérimentation de Google d'un Assistant Commercial IA intégré au SERP pour les requêtes shopping (C'est énorme ! Ici sur X, repéré par SERP Alert).
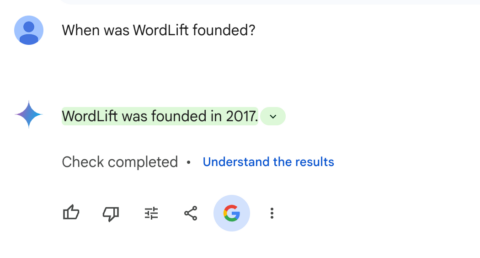 |
Voici un exemple de Gémeaux et Recherche Google partageant le même fait.
Validation et vérification des données
Les données structurées fournissent des mécanismes de vérification via :
- Graphiques de connaissances : Des systèmes comme Data Commons de Google utilisent des données structurées pour vérifier les faits.
- Ensembles de formation : Le balisage Schema.org crée des exemples de formation fiables pour la reconnaissance d'entités.
- Pipelines de validation : Les outils de génération de contenu, comme WordLift, utilisent des données structurées pour vérifier les sorties de l'IA.
La distinction clé est que les données structurées n'influencent pas directement les réponses LLM, mais façonnent plutôt les moteurs de recherche IA à travers :
- Données de formation qui incluent un balisage structuré.
- Définitions de classes d’entités qui guident la compréhension.
- Intégration avec les résultats riches de la recherche traditionnelle.
Cela rend la mise en œuvre de données structurées de plus en plus importante pour la visibilité sur les plateformes de recherche traditionnelles et basées sur l'IA.
Alors que nous entrons dans cette nouvelle ère de l’IA Discovery, investir dans les données structurées n’est plus seulement une question de référencement – il s'agit de construire la couche sémantique qui permet aux machines de vraiment comprendre et de représenter avec précision qui vous êtes..
Évolution du référencement sémantique : des données structurées aux données sémantiques
La pratique du référencement a évolué vers le référencement sémantique, allant au-delà de l'optimisation traditionnelle des mots clés pour englober la compréhension sémantique :
Optimisation basée sur l'entité
- Concentrez-vous sur des définitions et des relations claires entre les entités.
- Implémentation d’attributs d’entité complets.
- Utilisation stratégique des propriétés SameAs pour la désambiguïsation des entités.
Réseaux de contenu
- Développement de clusters de contenus interconnectés.
- Marquage clair de l’attribution et de la paternité.
- Définitions des relations Rich Media.
Modèles d'implémentation clés dans JSON-LD
Publication de contenu
L'analyse des modèles de données structurées sur des millions de sites Web révèle trois tendances dominantes en matière de mise en œuvre pour les éditeurs de contenu.
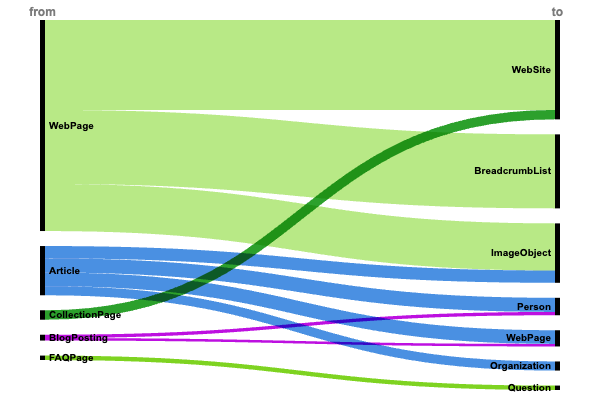
Structure et navigation du site Web (+6 millions d'implémentations)
La domination des relations WebPage → isPartOf → WebSite (5,8 millions) et WebPage → breadcrumb → BreadcrumbList (4,8 millions) démontre que les principaux sites Web donnent la priorité à une architecture de site et à des chemins de navigation clairs.
La structure du site reste le fondement de la mise en œuvre de données structurées, ce qui suggère que les moteurs de recherche s'appuient fortement sur ces signaux pour comprendre la hiérarchie du contenu.
Attribution et autorité du contenu
Des tendances fortes émergent autour de l’attribution de contenu :
- Article → auteur → Personne (925 000).
- Article → éditeur → Organisation (597 000).
- BlogPosting → auteur → Personne (217 000).
Cette focalisation sur la paternité et l'attribution organisationnelle reflète l'importance croissante des signaux EEAT et de l'autorité du contenu dans les algorithmes de recherche.
Intégration Rich Media
Implémentation cohérente du balisage d'image dans tous les types de contenu :
- Page Web → PrimaryImageOfPage → ImageObject (3 millions)
- Article → image → ImageObject (806 000)
La fréquence élevée des relations avec les médias indique que les éditeurs reconnaissent la valeur du contenu visuel structuré à la fois pour la visibilité dans les recherches et pour l'expérience utilisateur.
Les données suggèrent que les éditeurs vont au-delà du balisage SEO de base pour créer des graphiques de contenu complets lisibles par machine qui prennent en charge à la fois la recherche traditionnelle et les systèmes de découverte d'IA émergents.
Entreprise locale et vente au détail
L'analyse de la mise en œuvre des données structurées des entreprises locales révèle trois groupes de modèles critiques qui dominent le balisage basé sur l'emplacement.
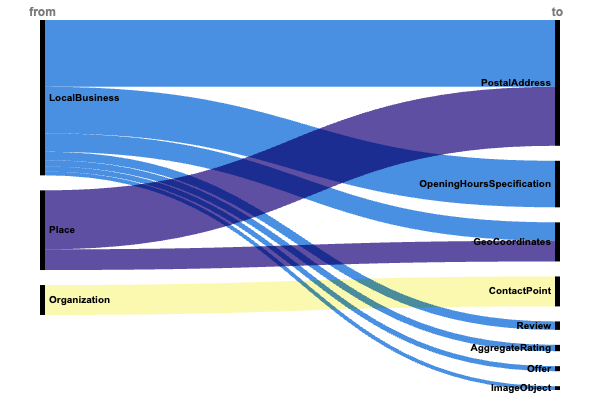
Emplacement et accessibilité (+1,4 million de mises en œuvre)
L'adoption massive du balisage d'emplacement physique démontre son importance fondamentale :
- LocalBusiness → adresse → PostalAddress (745 000).
- Lieu → adresse → PostalAddress (658 000).
- Organisation → contactPoint → ContactPoint (334 000).
- LocalBusiness → openingHoursSpecification (519 000).
La forte présence de ces détails opérationnels de base suggère qu’ils constituent des facteurs de classement essentiels pour la visibilité de la recherche locale.
Précision géographique
La mise en œuvre importante des géocoordonnées montre l’accent mis sur une localisation précise :
- Lieu → géo → GéoCoordonnées (231 000).
- LocalBusiness → géo → Géocoordonnées (205 000).
Cette double approche de la localisation (adresse + coordonnées) indique que les moteurs de recherche apprécient un positionnement géographique précis pour la précision de la recherche locale.
Signaux de confiance
Un groupe de modèles plus petit mais notable se concentre sur la réputation :
- LocalBusiness → avis → Avis (94 000)
- LocalBusiness → AggregateRating → AggregateRating (70 000)
- Entreprise Locale → photos → ObjetImage (42 000)
- LocalBusiness → faitOffre → Offre (56 000)
Bien que moins fréquemment mis en œuvre, ces éléments de confiance créent des entités commerciales locales plus riches qui soutiennent à la fois la visibilité des recherches et la prise de décision des utilisateurs.
Commerce électronique (liste étendue)
L'analyse des données structurées du commerce électronique révèle des modèles de mise en œuvre sophistiqués axés sur la découverte de produits et l'optimisation de la conversion.

Informations produit de base (+4,7 millions d'implémentations)
La prédominance du balisage de base des produits montre son importance fondamentale :
- Produit → offres → Offre (3,1 millions).
- Offre → vendeur → Organisation (2,2 millions).
- Produit → mainEntityOfPage → WebPage (1,5 million).
Ce taux d'adoption élevé des relations avec les produits de base indique leur rôle essentiel dans la découverte de produits et la visibilité des commerçants.
Confiance et preuve sociale
Implémentation significative du balisage lié aux avis :
- Produit → avis → Avis (490 000).
- Produit → AggregateRating → AggregateRating (201 000).
- Examen → évaluationNote → Note (110 000).
La présence importante du balisage des avis suggère que la preuve sociale reste cruciale pour la conversion en commerce électronique.
Contexte produit amélioré
La mise en œuvre d'attributs de produit enrichis met l'accent sur les informations détaillées sur le produit :
- Produit → marque → Marque (315 000).
- Produit → supplémentaireProperty → PropertyValue (253 000).
- Produit → image → ImageObject (182 000).
- Offre → détails d'expédition → OfferShippingDetails (151 000).
- Offre → Spécification de prix → Spécification de prix (42 000).
- AggregateOffer → offres → Offre (69 000).
Cette approche en couches des attributs du produit crée des entités de produit complètes qui prennent en charge à la fois la visibilité de la recherche et la prise de décision des utilisateurs.
Perspectives d'avenir
Le rôle des données structurées s'étend au-delà de leur fonction traditionnelle d'outil de référencement pour alimenter des extraits enrichis et des fonctionnalités de recherche spécifiques. À l’ère de la découverte de l’IA, les données structurées deviennent un outil essentiel pour la compréhension des machines, transformant la façon dont le contenu est interprété et connecté sur le Web. Ce changement pousse l'industrie à pensez au-delà de l'optimisation centrée sur Googleadoptant les données structurées comme composant essentiel d'un Web sémantique et intégré à l'IA.
Les données structurées fournissent l'échafaudage nécessaire à la création de cadres interconnectés et lisibles par machine, qui sont essentiels pour les applications d'IA émergentes telles que la recherche conversationnelle, les graphiques de connaissances et les systèmes de génération augmentée de récupération (Graph) (GraphRAG ou RAG). Cette évolution nécessite une double approche : exploiter des types de schémas exploitables pour des avantages SEO immédiats (résultats riches) tout en investissant dans des schémas descriptifs complets qui construisent un écosystème de données plus large.
L’avenir réside à l’intersection des données structurées, de la modélisation sémantique et des systèmes de découverte de contenu basés sur l’IA. En adoptant une vision plus holistique, les organisations peuvent passer de l’utilisation des données structurées comme ajout tactique au référencement à un positionnement stratégique pour alimenter les interactions de l’IA et garantir la trouvabilité sur diverses plates-formes.
Crédits et remerciements
Cette analyse ne serait pas possible sans le travail dévoué de l'équipe HTTP Archive et des contributeurs du Web Almanac. Un merci spécial à :
Le chapitre complet sur les données structurées du Web Almanac offre des informations encore plus approfondies sur le paysage évolutif de la mise en œuvre des données structurées.
À mesure que nous nous dirigeons vers un avenir fondé sur l’IA, l’importance stratégique des données structurées continuera de croître.
Plus de ressources :